Where AI is failing design systems, and where we are failing AI
For a design system program where the goal is often stable, high quality, durable output, how much instability, lack of quality, or impermanence can we tolerate in our tools? That’s the question Nathan Curtis and I asked the design system community for Episode 060 of The Question.
On August 21, 2025, Nathan and I facilitated a deep dive discussion into the data we gathered from 95 design system practitioners. We only asked two questions:
- Is there an expectation in your organization that digital interface production will be done with AI in the near future?
- Where, in your daily work, is AI too imprecise for your needs—where is it failing you?
As you might expect, the answers were complicated. In the discussion, we acknowledged that AI is really good at some parts of our process and pretty terrible at others. It turns out, the places where AI is failing design system may be the places we are failing AI.
Organizational context
In a lot of the work folks are doing to incorporate AI into design systems, AI’s inherently probabilistic output keeps bumping into the deterministic promises our systems must make. We think about our design systems as a contract—a promise we make to our consumers. By their very nature, the large language models that are disrupting every other segment of our work are very fast and really good guessers. But guessing isn’t what we promise.
Jesse expressed it well, “Our [IT] team wants the kind of security assurances that you can get from a deterministic system, which makes stochastic responses… difficult… from a security standpoint.”
While it’s not exactly the same, the phrase he used (“security assurances”) mostly maps to what we say design systems do best: establish reliable patterns, tested code, and shared language that product teams can trust. When you insert AI into the flow, the thing generating an answer might produce a different response each time you ask. In this case, that variety means eroded trust.
Deterministic contracts vs. probabilistic helpers
Nathan talked about holding both truths at once—use AI, but keep the contract deterministic: “This balance between predictive stochastic behavior and deterministic specification is the work… I might use AI to predict what the data might be, but the system still needs explicit specs.”
He’s right—the work is shifting from clever prompts to complex context. Others are calling this context engineering, and there’s a lot to it. If you’re someone who laughed at the idea that writing prompts could be a full time job (hey, I sure was), this is different.
Engineering context usually looks like entire systems constructing the necessary data, boundaries, instructions, output formats, and more so that what you get out of a system is much more controlled. You can imagine a scenario where these context engineering systems need tested and versioned, especially as context changes over time. This adds a whole new set of rows to your already growing RACI. Of course, this is a ton of work. And that’s where the conversation started to shift toward where AI is easy to make work and where it’s challenging.
A spectrum of precision
As I read through the raw data, I started to see a pattern in the AI successes and failures you shared. Most of you are likely familiar with the double diamond design process.
“The Double Diamond is a visual representation of the design and innovation process. It’s a simple way to describe the steps taken in any design and innovation project, irrespective of methods and tools used. The two diamonds represent a process of exploring an issue more widely or deeply (divergent thinking) and then taking focused action (convergent thinking).”
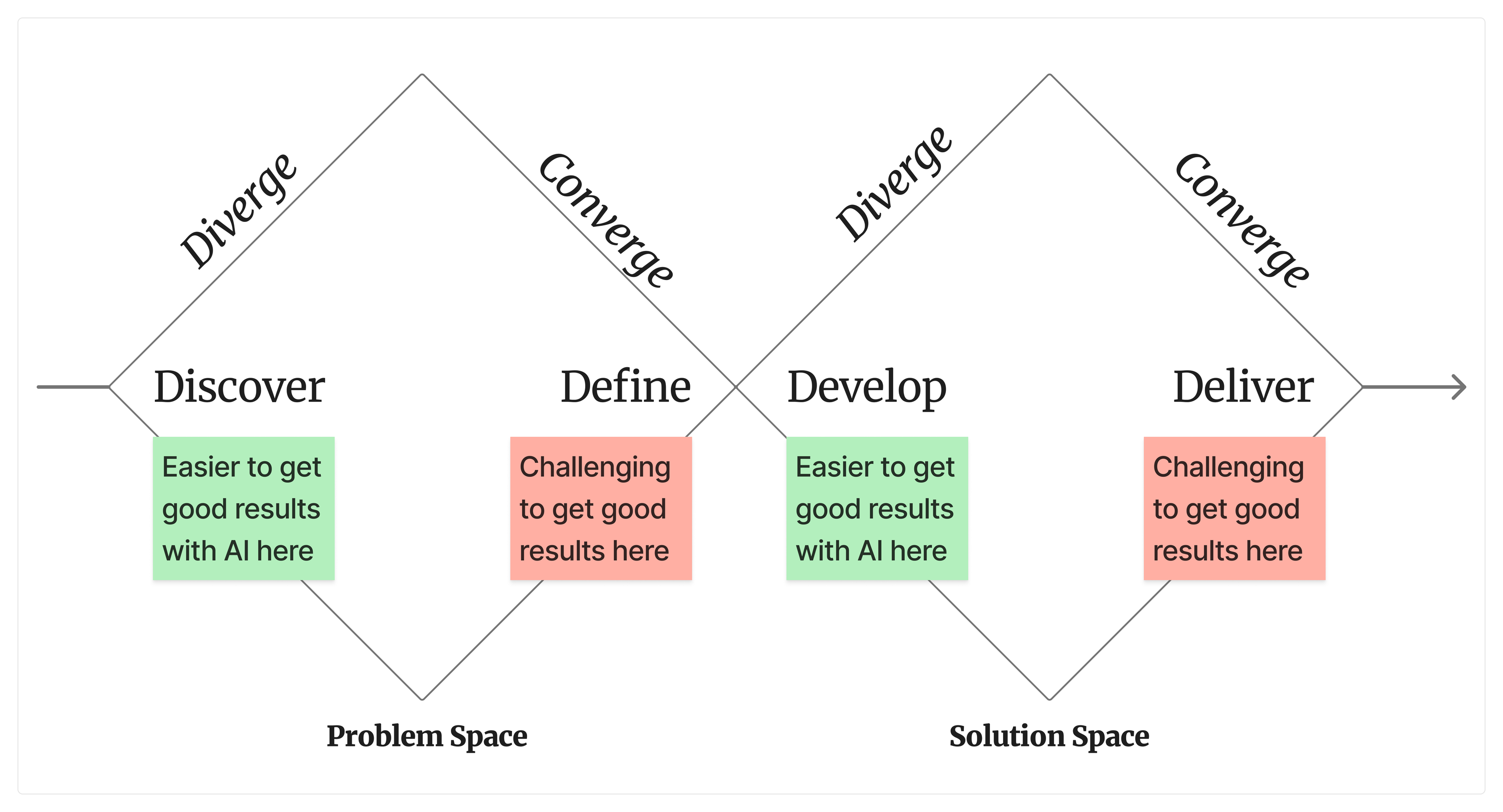 The Double Diamond Design Process—it seems easier to get successful AI results on the divergent sides of the diamonds than on the convergent sides.
The Double Diamond Design Process—it seems easier to get successful AI results on the divergent sides of the diamonds than on the convergent sides.
The pattern I saw in your answers hinted that it’s much easier to get the current generation of AI tools to help with divergent tasks, and much more challenging to get good AI results for convergent tasks.
On the left, imprecision is often fine—even helpful. On the right, it’s not. From the raw data, here’s what I heard:
Divergent, Where AI is working today: This included tasks like brainstorming, synthesizing notes, research assistance, throw-away prototypes, and repetitive or low-risk tasks. One respondent summed it up: “It does offer a quick starting point, and can automate some repetitive tasks.” (anonymized survey response)
Convergent, Where AI breaks trust: This included tasks like creating production-quality code, strict design-system fidelity, pixel-perfect visual decisions, and reproducibility. As one person put it: “No one trusts it to write shippable code right now, definitely not without proper review and testing.” (anonymized survey response)
Other thoughts from the raw data echoed the same pattern: “Figma Make does not adhere to our design system… even when prompted to do so.” And, “We only achieved about 80% accuracy… less than 100% doesn’t make sense to us.” (anonymized survey responses)
On component generation, one respondent was blunt: “It produces questionable results when generating new components… dual API, non-ideal TypeScript practices.” (anonymized survey response)
But you shared where it’s really helping too: “AI is great as a search engine and highlighting best practices,” wrote one respondent, while another shared that it’s “helping to automate the easy work and speed our workflows up.” (anonymized survey responses)
Lean in where it’s working, experiment where it’s not
From the discussion, the survey, and the working notes, here’s a simple model I’m taking forward:
Lean in where AI is working well
- Discovery & exploration (brainstorming, research, competitive analysis)
- Summaries & first drafts (high-level synthesis, summarizing meetings and notes)
- Structured refactors (bulk renames, token diff reports, CSS cleanups with clear specs)
- Low-risk prototyping (quick flows to discuss options, not for usability evidence)
Experiment where AI is not working well (yet)
- Design-system fidelity (“components/tokens must be exact”)
- Production code (“reproducibility > novelty”)
- Pixel-perfect visual decisions (“brand language and whitespace judgment still failing”)
- Consistency & repeatability (“you can give AI the same prompt multiple times, and get a different result”)
How to help on both sides:
- Context layering (MCP, RAG, repo access so models can see your system, not generic ones from the internet)
- Contract tests (schema checks, token linting, visual diffs, etc.)
- Remove preference (optimizations based on human preference don’t always lead to good results)
Some next steps
If you’re piloting or hardening AI in your DS program, here’s a few things you can do right away, pulled straight from the deep dive and raw data:
- Write down the contract. Name the nonnegotiables your system guarantees (APIs, accessibility rules, token semantics, etc) and instrument tests for them.
- Rigor on the convergent. Require rigorous checks when you cross into using AI for convergent tasks. If it touches published system assets, it must pass these tests.
- Measure confidence. Track the amount of AI output that’s accepted without edits, average cleanup time, and bugs or deviations caught after you roll out. That can become a measure of AI Confidence Debt, a phrase Brandon used in the deep dive.
- More intentional context. For example, you could annotate a small “style Bible” with 20 side-by-side right/wrong examples pulled from your product and use that as part of your context.
- Ask why. When AI doesn’t meet your expectations, make it part of your practice to ask for an explanation—perhaps digging into which design system guidelines the model relied on for the faulty output. In the long run, this may help your human users as much as your AI ones. (See XAI.).
To sum it all up, until a model can guarantee the promises your system makes, AI is best treated as a collaborator that scaffolds, accelerates, and proposes, not a factory that ships.
The human part is still the hard part
All of this has me thinking that the reasons AI is failing are the same reasons humans often fail. Without the right information to start, success is really hard.
I see this in my coaching practice every single day. 99% of the problems we work through are people problems. That doesn’t change just because you insert some brilliant AI model into your process. Murphy Trueman wrote about this recently:
“We’re pouring energy into the wrong places — we keep solving the wrong problems. Perfect component libraries, beautifully crafted tokens, extensive documentation sites that win awards. Meanwhile, teams are building around the system because it’s easier than using it.”
Just a reminder not to forget the humans on the other side of your components.
Find your community
Curious how others are doing this? Come hang with us in Redwoods. It’s a space for people who want to support each other on the journey of building better design system programs.
Learning mode
I am continually inspired by the people who participate week after week to dive into the answers we gather. Each one of you shows up in learning mode. Because of that, we all walk away with broadened perspectives and an appreciation for the experiences we each bring to these conversations.
To those of you who attended, thanks for joining with such a gracious posture.
Resources
- Review the Episode 060 Raw Data
- Review the Episode 060 FigJam
- Watch the Episode 060 Recap
- Connect with Nathan or Ben on LinkedIn
- Check out previous episodes of The Question
Thank you
Many thanks to all who participated.
If you missed out this week, sign up for The Question and be ready to answer next time.
Writing Design Systems The Question Featured
Join Redwoods, a design system community.
Sign up for The Question, a weekly design system deep dive.
Explore more of my writing and speaking.
Or, inquire about design system coaching